Someone just pointed me at this post from Ben Balter about Data as Code in which he emphasizes the analogies between data and code (and especially open data and open-source – e.g. “data is where code was 2 decades ago” …).
I was delighted to see this post as it makes many points I deeply agree with - and have for some time. In fact, reading it gave me something a sense of (very positive) deja-vu since it made similar points to several posts I and others had written several years ago - suggesting that perhaps we’re now getting close to the critical mass we need to create a real distributed and collaborative open data ecosystem!
It also suggested it was worth dusting off and recapping some of this earlier material as much of it was written more than 6 years ago, a period which, in tech terms, can seem like the stone age.
Previous Thinking
For example, there is this essay from 2007 on Componentization and Open Data that Jo Walsh and I wrote for our XTech talk that year on CKAN. It emphasized analogies with code and the importance of componentization and packaging.
This, in turn, was based on Four principles for Open Knowledge Development and What do we mean by componentization for knowledge. We also emphasized the importance of “version control” in facilitating distributed collaboration, for example in Collaborative Development of Data (2006/2007) and, more recently, in Distributed Revision Control for Data (2010) and this year in Git (and GitHub) for Data.
Package Managers and CKAN
This also brings me to a point relevant both to Ben’s post and Michal’s comment: the original purpose (and design) of CKAN was precisely to be a package manager a la rubygems, pypi, debian etc. It has evolved a lot from that into more of a “wordpress for data” - i.e. a platform for publishing, managing (and storing) data because of user demand. (Note that in early CKAN “datasets” were called packages in both the interface and code - a poor UX decision ;-) that illustrated we were definitely ahead of our time - or just wrong!)
Some sense of what was intended is evidenced by the fact that in 2007 we were writing a command line tool called datapkg (since changed to dpm for data package manager) to act at the command equivalent of gem / pip / apt-get - see this Introducting DataPkg post which included this diagram illustrating how things were supposed to work.

Recent Developments
As CKAN has evolved into a more general-purpose tool – with less of a focus on just being a registry supported automated access – we’ve continued to develop those ideas. For example:
- The basic “package” idea from CKAN has evolved into the Data Package spec - and Simple Data Format
- We’ve explored storing data using code tools like git - with a dedicated datasets organization on Github
- We’ve re-booted the idea of a simple registry and storage mechanism in the form of http://data.okfn.org/ - with data stored in simple data format in git repos on github, displayed in a very simple registry with good tool integration, and curated by a dedicated group of maintainers
- We’ve booted the “Frictionless Data” initiative as a way to bring together these different activities in one coherent vision of how we can do something simple to make progress
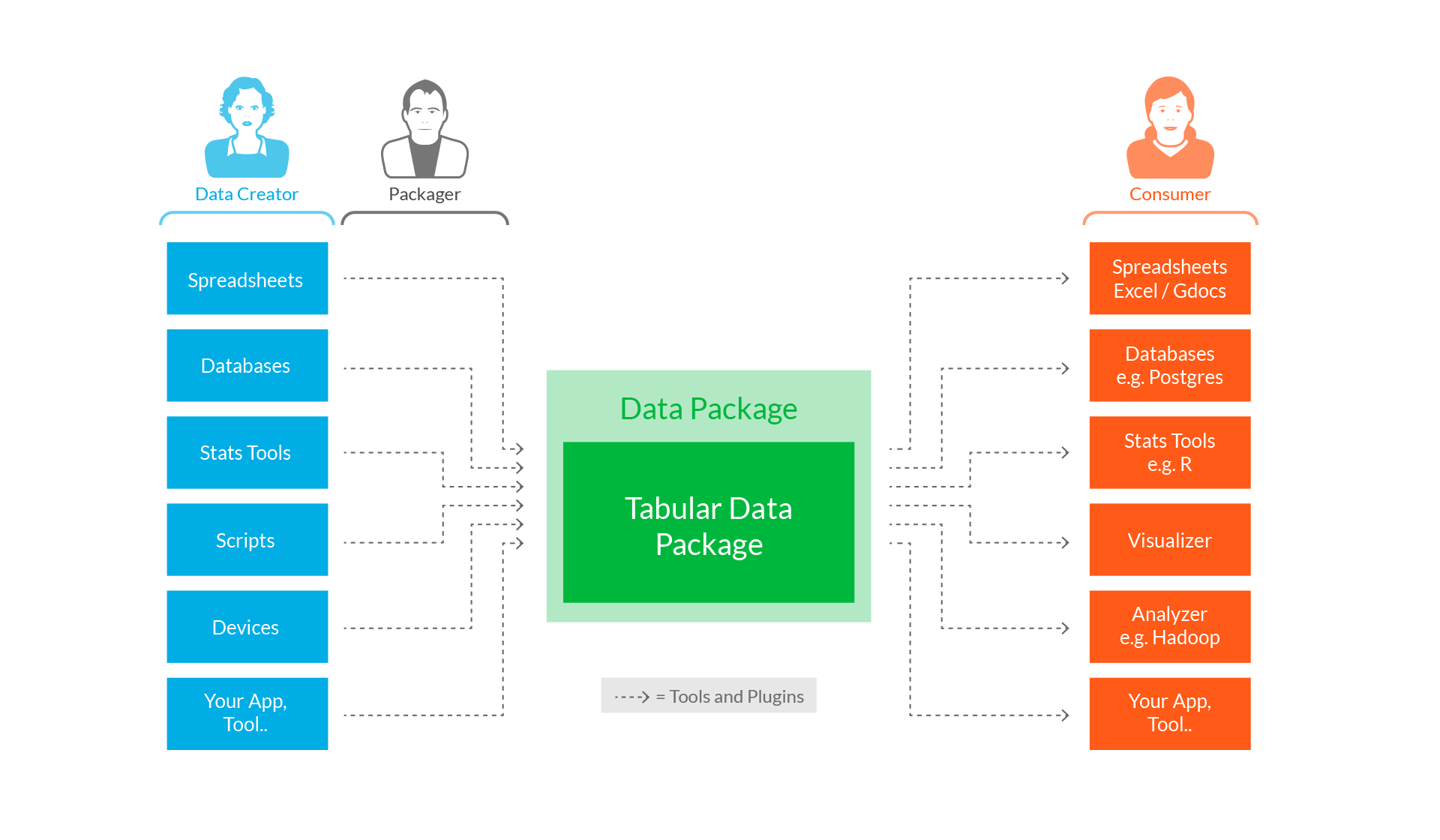
Data Packages and Frictionless Data - from data.okfn.org