In doing research for the EU Public Domain project (as here and here) we are often handling large datasets, for example one national library’s list of pre-1960 books stretched to over 4 million items. In such a situation, an algorithm’s speed (and space) can really matter. To illustrate, consider our ‘loading’ algorithm – i.e. the algorithm to load MARC records into the DB, which had the following steps:
- Do a simple load: i.e. for each catalogue entry create a new Item and new Persons for any authors listed
- “Consolidate” all the duplicate Persons, i.e. a Person who is really the same but for whom we create duplicate DB entries in part 1 (we can do this because MARC cataloguers try to uniquely identify authors based on name + birth date + death date).
- [Not discussed here] Consolidate “items” to “works” (associate multiple items (i.e. distinct catalogue entries) of, say, a Christmas Carol, to a single “work”)
The first part of this worked great: on a 1 million record load we averaged between 8s and 25s (depending on hardware, DB backend etc) per thousand records with speed fairly constant throughout (so that’s between 2.5 and 7.5h to load the whole lot). Unfortunately, at the consolidate stage we ran into problems: for a 1 million item DB there were several 100 thousand consolidations and we were averaging only 900s per 1000 consolidations! (This also scaled significantly with DB size: a 35k records DB averaged 55s per 1000). This would mean a full run would require several days! Even worse, because of the form of the algorithm (all the consolidation for a given person were done as a batch) we ran into memory issues on big datasets with some machines.
To address this we switched to performing “consolidation” on load, i.e. when creating each Item for a catalogue entry we’d search for existing authors who matched the information we had on that record. Unfortunately this had a huge impact on the load: time grew superlinearly and had already reached 300s per 1000 records at the 100k mark having started at 40 – Figure 1 plots this relationship. By extrapolation, 1M records would take 100 hours plus – almost a week!
At this point we went back to the original approach and tried optimizing the consolidation, first by switching to pure sql and then by adding some indexes on join tables (I’d always thought that foreign keys were auto indexed but it turned out not to be the case!). The first of these changes solved the memory issues, while the second resolved the speed problems providing a speedup of more than 30x (30s per 1000 rather 900s) and reduced the processing time from several days to a few hours.
Many more examples of this kind of issue could be provided. However, this one already serves to illustrate the two main points:
- With large datasets speed really matters
- Even with optimization algorithms can take a substantial time to run
Both of these have a significant impact on the speed, and form, of the development process. First, because one has to spend time optimizing and profiling – which like all experimentation is time-consuming. Second because longer run-times directly impact the rate at which results are obtained and development can proceed – often bugs or improvements only become obvious once one has run on a large dataset, plus any change to an algorithm that alters output requires that it be rerun.
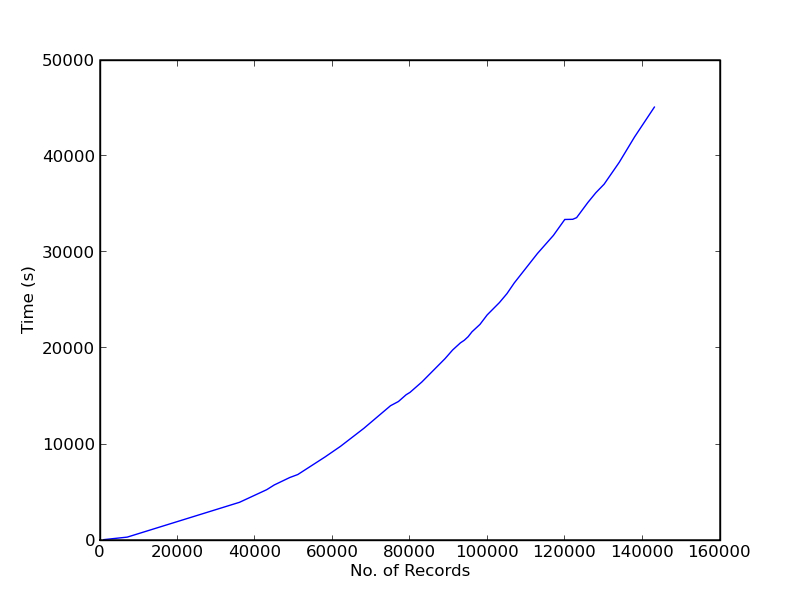
Figure 1: Load time when doing consolidation on load