Estimating Information Production and the Size of the Public Domain
Here we're going to look at using library catalogue data as a source for estimating information production (over time) and the size of the public domain.
Library Catalogues
Cultural institutions, primarily libraries, have long compiled records of the material they hold in the form of catalogues. Furthermore, most countries have had one or more libraries (usually the national library) whose task included an archival component and, hence, whose collections should be relatively comprehensive, at least as regards published material.
The catalogues of those libraries then provide an invaluable resource for charting, in the form of publications, levels of information production over time (subject, of course, to the obvious caveats about coverage and the relationship of general "information production" to publications).
Furthermore, library catalogue entries record (almost) the right sort of information for computing public domain status, in particular a given record usually has a) a publication date b) unambiguously identified author(s) with birth date(s) (though unfortunately not death date). Thus, we can also use this catalogue data to estimate the size of the public domain – size being equated here to the total number of items currently in the public domain.
Results
To illustrate, here are some results based on the catalogue of Cambridge University Library which is one of the UK's "copyright libraries" (i.e. they have a right to obtain, though not an obligation to hold, one copy of every book published in the UK). This first plot shows the numbers of publications per year (as determined by their publication date) up until 1960 (when the dataset ends) based on the publication date recorded in the catalogue.
A major concern when basing an analysis on these kinds of trends is is that fluctuations over time derive not from changes in underlying production and publication rates but changes in acquisition policies of the library concerned. To check for this, we present a second plot which shows the same information but derived from the British Library's catalogue. Reassuringly, though there are differences, the basic patterns look remarkably similar.
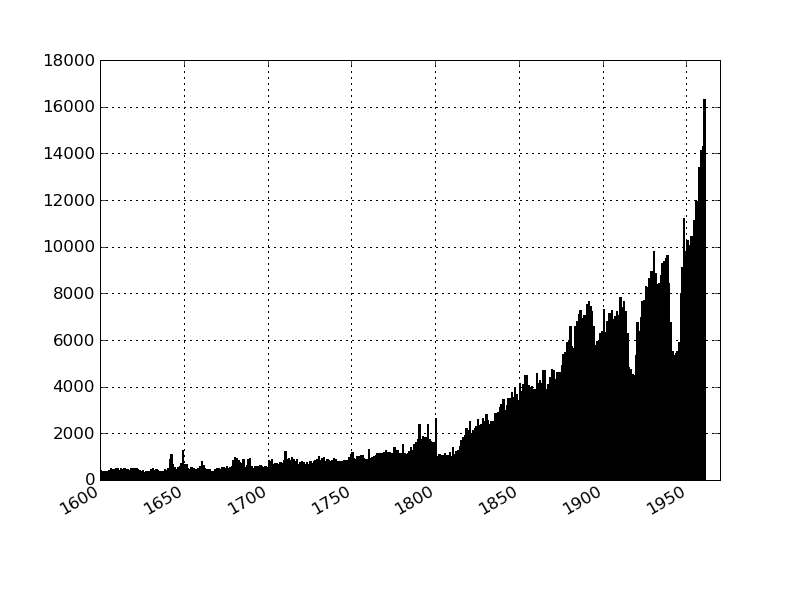
Number of items (books etc) Per Year in the Cambridge University Library Catalogue (1600-1960).
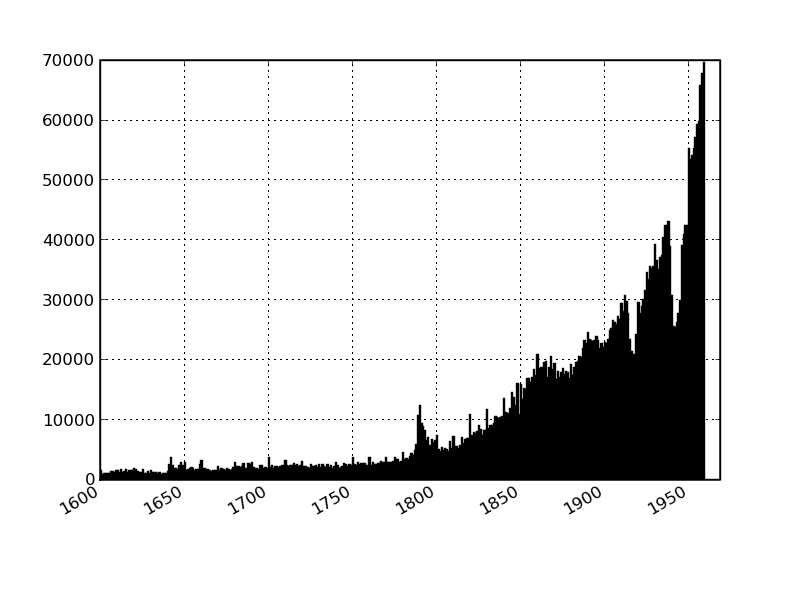
Number of items (books etc) Per Year in the British Library Catalogue (1600-1960).
What do we learn from these graphs?
- In total there were over a million "Items" in this dataset (and parsing, cleaning, loading and analyzing this data took on the order of days – while the preparation work to develop and perfect these algorithms took weeks if not months)
- The main trend is a fairly consistent, and approximately exponential, increase in the number of publications (items) per year. At the start of our time period in 1600 we have around 400 items a year in the catalogue while by 1960 the number is over 16000.
- This is a forty-fold increase and corresponds to an annual growth rate of approx 0.8%. Assuming "growth" began only around the time of the industrial revolution (~ 1750) when output was around 1000 (10-year moving average) gives a fairly similar growth rate of around 0.89%.
- There are some fairly noticeable fluctuations around this basic trend:
- There appears to be a burst in publications in the decade or decade and a half before 1800. One can conjecture several, more or less intriguing, reasons for this: the cultural impact of the French revolution (esp. on radicalism), the effect of loosening copyright laws after Donaldson v. Beckett, etc. However, without substantial additional work, for example to examine the content of the publications in that period these must remain little more than conjectures.
- The two world wars appear dramatically in our dataset as sharp dips: the pre-1914 level of around 7k+ falls by over a third during the war to around 4.5k and then rises rapidly again to reach, and pass, 7k per year in the early 20s. Similarly, the late 1930s level of around 9.5k per year drops sharply upon the outbreak of war reaching a low of 5350 in 1942 (a drop of 45%), and then rebounding rapidly at the war's end: from 5.9k in 1945 to 8k in 1946, 9k in 1947 and 11k in 1948!
To do next (but in separate entries – this post is already rather long!):
- Estimates for the the size of the public domain: how many of those catalogue items are in the public domain
- Distinguishing Publications ("Items") from "Works" – i.e. production of new material versus the reissuance of old (see previous post for more on this).
Colophon: Background to this Research
I'm working on a EU funded project on the Public Domain in Europe, with particular focus on the size and value of the public domain. This involves getting large datasets about cultural material and trying to answer questions like: How many of these items are in the public domain? What's the difference in price and availability of public domain versus non public domain items?
I've also been involved for several years in Public Domain Works, a project to create a database of works which were in the public domain.
Colophon: Data and Code
All the code used in parsing, loading and analysis is open and available from the Public Domain Works mercurial repository. Unfortunately, the library catalogue data is not: library catalogue data, at least in the UK, appears to be largely proprietary and the raw data kindly made available to us for the purposes of this research by the British Library and Cambridge University Library was provided only on a strictly confidential basis.