Data Pipes provides an online service built in NodeJS to do simple data transformations – deleting rows and columns, find and replace, filtering, viewing as HTML – and, furthermore, to connect these transformations together Unix pipes style to make more complex transformations. Because Data Pipes is a web service, data transformation with Data Pipes takes place entirely online and the results and process are completely shareable simply by sharing the URL.
An example
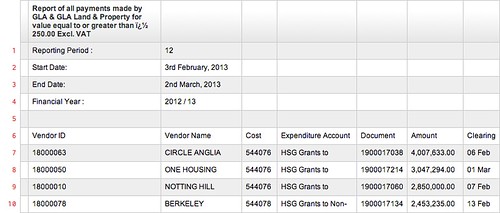
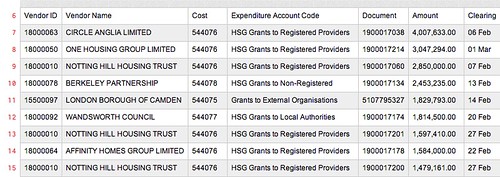
This takes the input data (sourced from this original Greater London Authority financial data), slices out the first 50 rows (head), deletes the first column (its blank!) (cut), deletes rows 1 through 7 (delete) and finally renders the result as HTML (html).
Before
After
Motivation - Data Wrangling, Pipes, NodeJS and the Unix Philosophy
When you find data in the wild you usually need to poke around in it and then to some cleaning for it to be usable.
Much of the inspiration for Data Pipes comes from our experience using Unix command lines tools like grep, sed, and head to do this kind of work. These tools a powerful way to operate on streams of text (or more precisely streams of lines of text, since Unix tools process text files line by line). By using streams, they can scale to large files easily (they don’t load the whole file but process it bit by bit) and, more importantly, allow “piping” – that is, direct connection of the output of one command with the input of another.
This already provides quite a powerful way to do data wrangling (see here for more). But there are limits: data isn’t always line-oriented, plus command line tools aren’t online, so it’s difficult to share and repeat what you are doing. Inspired by a combination of Unix pipes and the possibilities of NodeJS’s great streaming capabilities, we wanted to take the pipes online for data processing – and so Data Pipes was born.
We wanted to use the Unix philosophy that teaches us to solve problems with cascades of simple, composable operations that manipulate streams, an approach which has proven almost universally effective.
Data Pipes brings the Unix philosophy and the Unix pipes style to online data. Any CSV data can be piped through a cascade of transformations to produce a modified dataset, without ever downloading the data and with no need for your own backend. Being online means that the operations are immediately shareable and linkable.
More Examples
Take, for example, this copy of a set of Greater London Authority financial data. It’s unusable for most purposes, simply because it doesn’t abide by the CSV convention that the first line should contain the headers of the table. The header is preceded by six lines of useless commentary. Another problem is that the first column is totally empty.

First of all, let’s use the Data Pipes html operation to get a nicer-looking view of the table.
GET /csv/html/?url=http://static.london.gov.uk/gla/expenditure/docs/2012-13-P12-250.csv
Now let’s get rid of those first six lines and the empty column. We can do this by chaining together the delete operation and the cut operation:
GET /csv/delete 0:6/cut 0/html/?url=http://static.london.gov.uk/gla/expenditure/docs/2012-13-P12-250.csv
And just like that, we’ve got a well-formed CSV!
But why stop there? Why not take the output of that transformation and, say, search it for the string “LONDON” with the grep transform, then take just the first 20 entries with head?
GET /csv/delete 0:6/cut 0/grep LONDON/head -n 20/html/?url=http://static.london.gov.uk/gla/expenditure/docs/2012-13-P12-250.csv
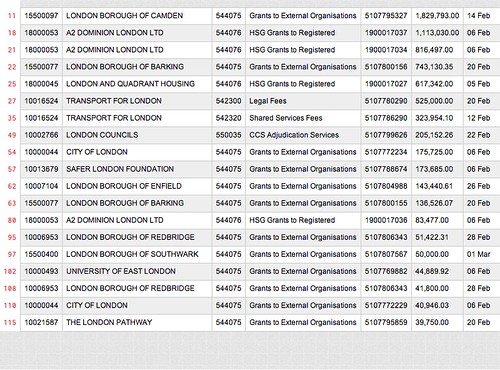
Awesome!
What’s next?
Data Pipes already supports a useful collection of operations, but it’s still in development, and more are yet to come, including find-and-replace operation sed plus support for arbitrary map and filter functions.
You can see the full list on the Data Pipes site, and you can suggest more transforms to implement by raising an issue.
Data Pipes needs more operations for its toolkit. That means its developers need to know what you do with data – and to think about how it can be broken down in the grand old Unix fashion. To join in, check out Data Pipes on GitHub and let us know what you think.